1
2
| import numpy as np
import pandas as pd
|
数据读取
1
| dataset = pd.read_csv("./flavors_of_cacao.csv")
|
1
2
3
| dataset.columns = dataset.columns.map(lambda x:x.replace("\n"," "))
dataset.columns = dataset.columns.map(lambda x:x.replace("\xa0",""))
dataset.info()
|
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1795 entries, 0 to 1794
Data columns (total 9 columns):
Company (Maker-if known) 1795 non-null object
Specific Bean Origin or Bar Name 1795 non-null object
REF 1795 non-null int64
Review Date 1795 non-null int64
Cocoa Percent 1795 non-null object
Company Location 1795 non-null object
Rating 1795 non-null float64
Bean Type 1794 non-null object
Broad Bean Origin 1794 non-null object
dtypes: float64(1), int64(2), object(6)
memory usage: 126.3+ KB
每个列的含义如下:
- Company:生产公司
- Specific Bean Origin or Bar Name:产品名称
- REF:不祥
- Review Date:
- Cocoa Percent:可可含量
- Company Location:公司地址
- Rating:等级
- Bean Type:可可豆类型
- Broad Bean Origin:原产地
数据预处理
缺失值丢弃
1
2
3
| dataset_nona = dataset.dropna()
dataset_nona = dataset_nona.drop(["REF"],axis=1)
dataset_nona.info()
|
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1793 entries, 0 to 1794
Data columns (total 8 columns):
Company (Maker-if known) 1793 non-null object
Specific Bean Origin or Bar Name 1793 non-null object
Review Date 1793 non-null int64
Cocoa Percent 1793 non-null object
Company Location 1793 non-null object
Rating 1793 non-null float64
Bean Type 1793 non-null object
Broad Bean Origin 1793 non-null object
dtypes: float64(1), int64(1), object(6)
memory usage: 126.1+ KB
百分比转换
1
2
| dataset_nona["Cocoa Percent"] = dataset_nona["Cocoa Percent"].map(lambda x:float(x.strip('%')) / 100)
dataset_nona.info()
|
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1793 entries, 0 to 1794
Data columns (total 8 columns):
Company (Maker-if known) 1793 non-null object
Specific Bean Origin or Bar Name 1793 non-null object
Review Date 1793 non-null int64
Cocoa Percent 1793 non-null float64
Company Location 1793 non-null object
Rating 1793 non-null float64
Bean Type 1793 non-null object
Broad Bean Origin 1793 non-null object
dtypes: float64(2), int64(1), object(5)
memory usage: 126.1+ KB
问题分析
Where are the best cocoa beans grown?
1
| best_been = dataset_nona[["Broad Bean Origin","Rating"]]
|
1
2
3
| best_been_data = best_been.groupby(["Broad Bean Origin"]).apply(np.mean)
best_been_data.sort_values(by="Rating",inplace=True)
print(best_been_data[-10:])
|
Rating
Broad Bean Origin
Dominican Rep., Bali 3.75
Peru, Belize 3.75
Ven.,Ecu.,Peru,Nic. 3.75
DR, Ecuador, Peru 3.75
Venez,Africa,Brasil,Peru,Mex 3.75
Dom. Rep., Madagascar 4.00
Venezuela, Java 4.00
Gre., PNG, Haw., Haiti, Mad 4.00
Guat., D.R., Peru, Mad., PNG 4.00
Peru, Dom. Rep 4.00
可看出最好的可可豆生长在秘鲁的Dom. Rep,危地马拉的D.R., Peru, Mad., PNG等地
Which countries produce the highest-rated bars?
1
2
| best_country = dataset_nona[["Company Location","Rating"]]
best_country.info()
|
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1793 entries, 0 to 1794
Data columns (total 2 columns):
Company Location 1793 non-null object
Rating 1793 non-null float64
dtypes: float64(1), object(1)
memory usage: 42.0+ KB
1
2
3
| best_country_data = best_country.groupby(["Company Location"]).apply(np.mean)
best_country_data.sort_values(by=["Rating"],inplace=True)
print(best_country_data[-10:])
|
Rating
Company Location
Guatemala 3.350000
Australia 3.357143
Poland 3.375000
Brazil 3.397059
Vietnam 3.409091
Iceland 3.416667
Philippines 3.500000
Netherlands 3.500000
Amsterdam 3.500000
Chile 3.750000
可以看出生产出巧克力较好的是智利,荷兰等地
what’s the relationship between cocoa solids percentage and rating?
1
2
3
| best_coco = dataset_nona[["Cocoa Percent","Rating"]]
best_coco.columns = best_coco.columns.map(lambda x:x.replace(" ",""))
best_coco.info()
|
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1793 entries, 0 to 1794
Data columns (total 2 columns):
CocoaPercent 1793 non-null float64
Rating 1793 non-null float64
dtypes: float64(2)
memory usage: 42.0 KB
CocoaPercent Rating
CocoaPercent 1.000000 -0.164758
Rating -0.164758 1.000000
1
2
3
4
5
| import matplotlib.pyplot as plt
plt.close()
plt.scatter(best_coco["CocoaPercent"].values,best_coco["Rating"].values)
plt.show()
|
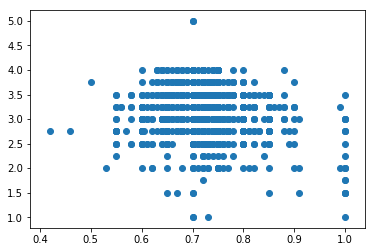
可以看出巧克力质量和含可可量没有明显的关系
探索分析
1
| print(dataset_nona.groupby(["Review Date"]).apply(lambda x:x["Rating"].sum() / x.shape[0]))
|
Review Date
2006 3.125000
2007 3.162338
2008 2.994624
2009 3.073171
2010 3.148649
2011 3.251524
2012 3.181701
2013 3.197011
2014 3.189271
2015 3.246491
2016 3.226027
2017 3.312500
dtype: float64
1
2
3
| coco_type = dataset_nona[["Bean Type","Rating"]]
coco_type = coco_type.groupby(["Bean Type"]).apply(np.mean)
print(coco_type.sort_values(by="Rating")[-10:])
|
Rating
Bean Type
Amazon, ICS 3.625
Criollo (Ocumare 77) 3.750
Trinitario, TCGA 3.750
Blend-Forastero,Criollo 3.750
Amazon mix 3.750
Trinitario, Nacional 3.750
Forastero (Amelonado) 3.750
Trinitario (85% Criollo) 3.875
Criollo (Wild) 4.000
Criollo (Ocumare 67) 4.000
最好的可可豆是Criollo
