Octave卷积
Octave卷积的主题思想来自于图片的分频思想,首先认为图像可进行分频:
- 低频部分:图像低频部分保存图像的大体信息,信息数据量较少
- 高频部分:图像高频部分保留图像的细节信息,信息数据量较大
由此,认为卷积神经网络中的feature map也可以进行分频,可按channel分为高频部分和低频部分,如图所示:
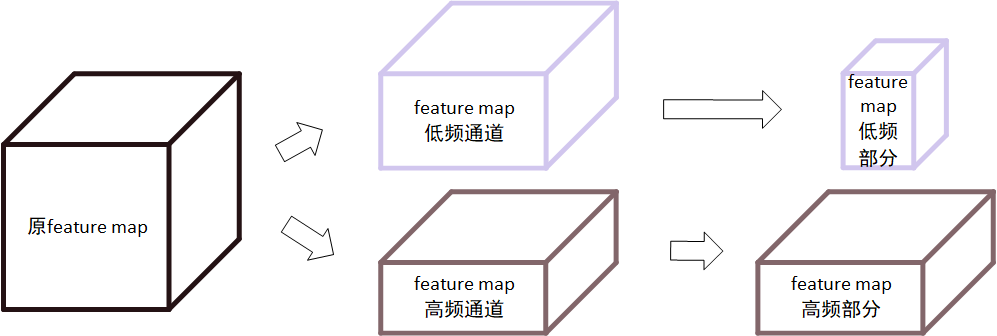
对于一个feature map,将其按通道分为两个部分,分别为低频通道和高频通道。随后将低频通道的长宽各缩减一半,则将一个feature map分为了高频和低频两个部分,即为Octave卷积处理的基本feature map,使用X表示,该类型X可表示为$X = [X^H,X^L]$,其中$X^H$为高频部分,$X^L$为低频部分。
为了处理这种结构的feature map,其使用了如下所示的Octave卷积操作:
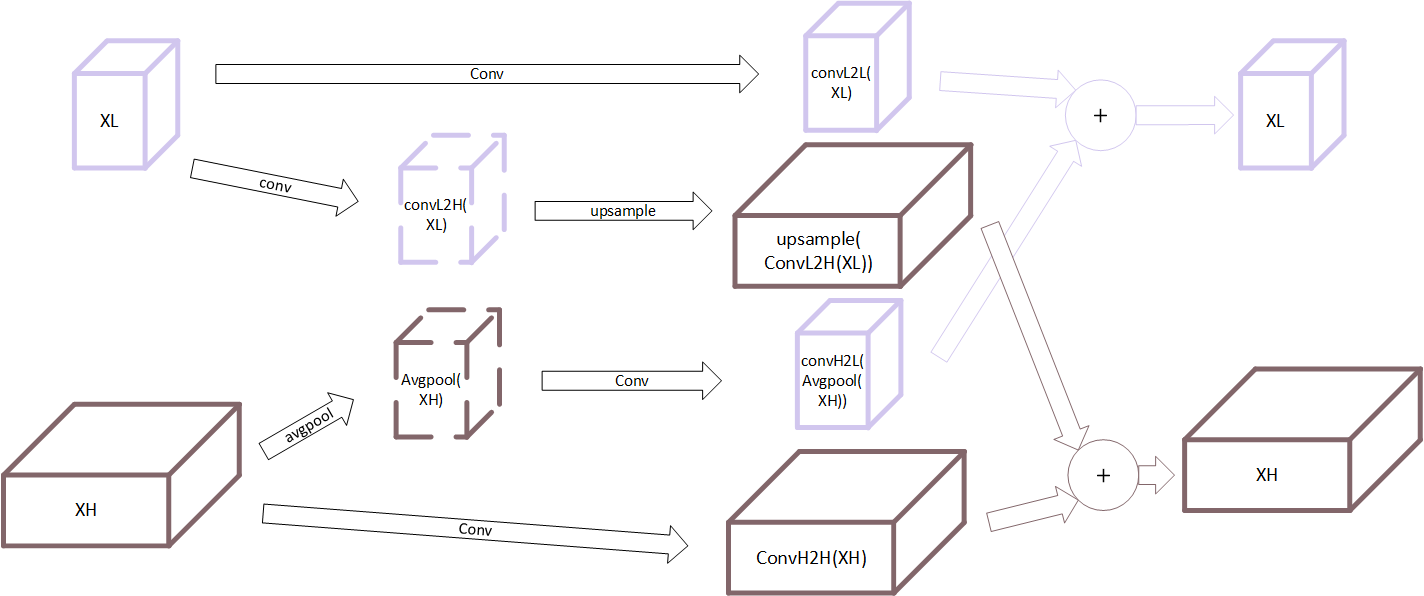
首先考虑低频部分输入$X^L$,该部分进行两个部分的操作:
- $X^L \to X^H$:从低频到高频,首先使用指定卷积核$W^{L \to H}$进行卷积,随后进行Upample操作生成与高频部分长宽相同的Tensor,最终产生$Y^{L\to H} = Upsample(Conv(X^L,W^{L \to H}),2)$
- $X^L \to X^L$:从低频到低频,这个部分为直接进行卷积操作$Y^{L \to L} = Conv(X^L,W^{L \to L})$
随后考虑高频部分,与低频部分类似有两个部分的操作:
- $X^H \to X^H$:从高频到高频,直接进行卷积操作$Y^{H \to H} = Conv(X^H,W^{H \to H})$
- $X^H \to X^L$:从高频到低频,首先进行stride和kernel均为2的平均值池化,再进行卷积操作,生成与$Y^L$通道数相同的feature map,最终产生$Y^{H \to L} = conv(avgpool(X^H,2),W^{H \to L}))$
最终,有$Y^L = Y^{H \to L} + Y^{L \to L}$和$Y^H = Y^{H \to H} +Y^{L \to H}$,因此可以总结如下公式:
因此有四个部分的权值:
| 来源/去向 | $\to H$ | $\to L$ |
|---|---|---|
| H | $W^{H \to H}$ | $W^{H \to L}$ |
| L | $W^{L \to H}$ | $W^{L \to L}$ |
另外进行使用时,在网络的输入和输出需要将两个频率上的Tensor聚合,做法如下:
- 输入部分,取$X = [X,0]$,即有$X^H = X$,$X^L = 0$,仅进行$H \to L$和$H \to H$操作,输出输出的低频仅有X生成,即$Y^H = Y^{H \to H}$和$Y^L = Y^{H \to L}$
- 输出部分,取$X = [X^H,X^L]$,$\alpha = 0$。即仅进行$L \to H$和$H \to H$的操作,最终输出为$Y = Y^{L \to H} + Y^{H \to H}$
性能分析
以下计算均取原Tensor尺寸为$CI \times W \times H$,卷积尺寸为$CO \times CI \times K \times K$,输出Tensor尺寸为$CO \times W \times H$(stride=1,padding设置使feature map尺寸不变)。
计算量分析
Octave卷积的最大优势在于减小计算量,取参数$\alpha$为低频通道占总通道的比例。首先考虑直接卷积的计算量,对于输出feature map中的每个数据,需要进行$CI \times K \times K$次乘加计算,因此总的计算量为:
现考虑Octave卷积,有四个卷积操作:
- $L \to L$卷积:$C{L \to L} = \alpha^2 \times (CO \times \frac{W}{2} \times \frac{H}{2}) \times (CI \times K \times K) = \frac{\alpha^2}{4} \times C{conv}$
- $L \to H$卷积:$C{L \to H} = ((1 - \alpha) \times CO \times \frac{W}{2} \times \frac{H}{2}) \times ( \alpha \times CI \times K \times K) = \frac{\alpha(1-\alpha)}{4} \times C{conv}$
- $H \to L$卷积:$C{H \to L} = (\alpha \times CO \times \frac{W}{2} \times \frac{H}{2}) \times ((1 - \alpha) \times CI \times K \times K) = \frac{\alpha(1-\alpha)}{4} \times C{conv}$
- $H \to H$卷积:$C{H \to H} = ((1 - \alpha) \times CO \times W \times H) \times ((1 - \alpha) \times CI \times K \times K) = (1 - \alpha)^2 \times C{conv}$
总上,可以得出计算量有:
在$\alpha \in [0,1]$中单调递减,当取$\alpha = 1$时,有$\frac{C{octave}}{C{conv}} = \frac{1}{4}$。
参数量分析
原卷积的参数量为:
Octave卷积将该部分分为四个,对于每个卷积有:
- $L \to L$卷积:$W{L \to L} =(\alpha\times CO) \times (\alpha \times CI) \times K \times K = \alpha^2 \times W{conv}$
- $L \to H$卷积:$W{L \to H} =((1-\alpha) \times CO) \times (\alpha \times CI) \times K \times K = \alpha(1 - \alpha) \times W{conv}$
- $H \to L$卷积:$W{H \to L} =(\alpha \times CO) \times ((1-\alpha) \times CI) \times K \times K = \alpha(1 - \alpha) \times W{conv}$
- $H \to H$卷积:$W{H \to L} =((1-\alpha) \times CO) \times ((1-\alpha) \times CI) \times K \times K = (1 - \alpha)^2 \times W{conv}$
因此共有参数量:
由此,参数量没有发生变化,该方法无法减少参数量。
Octave卷积实现
Octave卷积模块
以下实现了一个兼容普通卷积的Octave卷积模块,针对不同的高频低频feature map的通道数,分为以下几种情况:
Lout_channel != 0 and Lin_channel != 0:通用Octave卷积,需要四个卷积参数Lout_channel == 0 and Lin_channel != 0:输出Octave卷积,输入有低频部分,输出无低频部分,仅需要两个卷积参数Lout_channel != 0 and Lin_channel == 0:输入Octave卷积,输入无低频部分,输出有低频部分,仅需要两个卷积参数Lout_channel == 0 and Lin_channel == 0:退化为普通卷积,输入输出均无低频部分,仅有一个卷积参数
1 | class OctaveConv(pt.nn.Module): |
在前项传播的过程中,根据是否有对应的卷积操作参数判断是否进行卷积,若不进行卷积,将输出置为0。前向传播时,输入为低频和高频两个feature map,输出为低频和高频两个feature map,输入情况和参数配置应与通道数的配置匹配。
其他部分
使用MNIST数据集,构建了一个三层卷积+两层全连接层的神经网络,使用Adam优化器训练,代价函数使用交叉熵函数,训练3轮,最后在测试集上进行测试。
1 | import torch as pt |
最终获得模型的准确率为0.988
