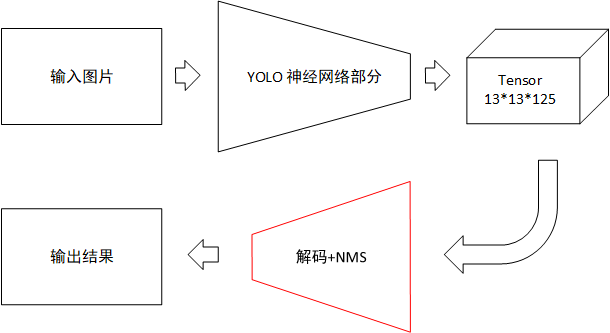
理论分析 YOLO从v2版本开始重新启用anchor box,YOLOv2网络的网络输出为尺寸为[b,125,13,13]的tensor,要将这个Tensor变为最终的输出结果,还需要以下的处理:
解码:从Tensor中解析出所有框的位置信息和类别信息
NMS:筛选最能表现物品的识别框
解码过程 解码之前,需要明确的是每个候选框需要5+class_num个数据,分别是相对位置x,y,相对宽度w,h,置信度c和class_num个分类结果,YOLOv2-voc中class_num=20,即每个格点对应5个候选框,每个候选框有5+20=25个参数,这就是为什么输出Tensor的最后一维为5*(20+5)=125。
上图为一个框所需要的所有数据构成,假设这个框是位于格点X,Y的,对应的anchor box大小为W,H,位置相关参数的处理方法如下所示,其中,$T_x,T_y$分别是输出Tensor在长宽上的值,这里$T_x = 13,T_y = 13$;$P_x,P_y$分别为原图片的长和宽:
置信度和类别信息处理方法如下所示:
当格点置信度大于某个阈值时,认为该格点有物体,物体类别为class_id对应的类别
NMS NMS为非最大值抑制,用在YOLO系统中的含义指从多个候选框标记同一个物品时,从中选择最合适的候选框。其基本思维很简单:使用置信度最高的候选框标记一个物体,若其他候选框与该候选框的IOU超过一个阈值,则认为其他候选框与该候选框标记的是同一个物体,丢弃其他候选框。
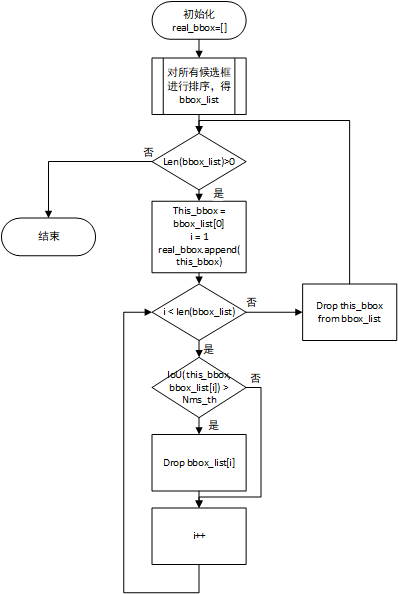
具体实现时,可以将所有候选框进行排序,置信度高的在前,置信度低的在后。从置信度高的候选框开始遍历所有候选框,对于某一个候选框,将之后所有的候选框与其计算IOU,若IOU高于一个阈值,则丢弃置信度低的候选框。算法流程图如下所示:
代码分析 这里选择的是marvis 开源的基于Pytorch的YOLOv2代码,其优势在于所有的部分均使用Python实现,没有使用Cython,无需编译即可使用,且依赖较少,文件管理比较扁平。
解码部分 解码部分在utils.py文件中,由get_region_boxes函数实现。首先是准备部分,这里首先获取了输出的相关信息,yolo-voc网络下有b为batch,预测模式下一般为1,h=w=13。随后reshape了输出,其维度变为(25,13*13*5),改变维度的目的是方便后面处理的索引。
1 2 3 4 5 6 7 8 9 10 11 def get_region_boxes (output, conf_thresh, num_classes, anchors, num_anchors, only_objectness=1 , validation=False ): anchor_step = len (anchors) / num_anchors if output.dim() == 3 : output = output.unsqueeze(0 ) batch = output.size(0 ) assert (output.size(1 ) == (5 + num_classes) * num_anchors) h = output.size(2 ) w = output.size(3 ) output = output.view(batch * num_anchors, 5 + num_classes, h * w).transpose( 0 , 1 ).contiguous().view(5 + num_classes, batch * num_anchors * h * w) all_boxes = []
随后是处理x,y的部分,xs和ys就是处理后的候选框中心点相对坐标,grid_x和grid_y与output[0]shape相同,分别表示对应output位置的候选框所属的格点坐标X与Y,这里的xs和ys实现了上述公式中的$xs = sigmoid(x) + X$和$ys = sigmoid(y) + Y$
1 2 3 4 5 6 7 grid_x = torch.linspace(0 , w - 1 , w).repeat(h, 1 ).repeat(batch * num_anchors, 1 , 1 ).view(batch * num_anchors * h * w).cuda() grid_y = torch.linspace(0 , h - 1 , h).repeat(w, 1 ).t().repeat( batch * num_anchors, 1 , 1 ).view(batch * num_anchors * h * w).cuda() print("outputs shape" , output.shape) xs = torch.sigmoid(output[0 ]) + grid_x ys = torch.sigmoid(output[1 ]) + grid_y
之后为处理w,h的部分,与处理x,y的部分类似,最终ws和hs为修正后的物品尺寸信息,实现了$ws = e^w\cdot W$和$hs = e^{h} \cdot H$。其中W和H分别为当前anchor box的建议尺寸。
1 2 3 4 5 6 7 8 9 10 anchor_w = torch.Tensor(anchors).view( num_anchors, anchor_step).index_select(1 , torch.LongTensor([0 ])) anchor_h = torch.Tensor(anchors).view( num_anchors, anchor_step).index_select(1 , torch.LongTensor([1 ])) anchor_w = anchor_w.repeat(batch, 1 ).repeat( 1 , 1 , h * w).view(batch * num_anchors * h * w).cuda() anchor_h = anchor_h.repeat(batch, 1 ).repeat( 1 , 1 , h * w).view(batch * num_anchors * h * w).cuda() ws = torch.exp(output[2 ]) * anchor_w hs = torch.exp(output[3 ]) * anchor_h
接下来是获取置信度的部分和类别部分,获取该anchor box的置信度为det_confs=sigmoid(c)。随后处理类别信息,先对类别信息对应的数据做softmax操作,随后获取其最大值cls_max_confs和最大值所在的位置cls_max_ids,其中位置cls_max_ids对应每个anchor box框住的“物品”的类别。
1 2 3 4 5 6 det_confs = torch.sigmoid(output[4 ]) cls_confs = torch.nn.Softmax()( Variable(output[5 :5 + num_classes].transpose(0 , 1 ))).data cls_max_confs, cls_max_ids = torch.max (cls_confs, 1 ) cls_max_confs = cls_max_confs.view(-1 ) cls_max_ids = cls_max_ids.view(-1 )
随后是一些其他的处理过程,例如获取格点数量sz_hw,anchor box的数量sz_hwa等,函数convert2cpu是在CPU上复制一个该数据,注意这里是拷贝,并不是将数据从GPU转移到CPU上。
1 2 3 4 5 6 7 8 9 10 11 sz_hw = h * w sz_hwa = sz_hw * num_anchors det_confs = convert2cpu(det_confs) cls_max_confs = convert2cpu(cls_max_confs) cls_max_ids = convert2cpu_long(cls_max_ids) xs = convert2cpu(xs) ys = convert2cpu(ys) ws = convert2cpu(ws) hs = convert2cpu(hs) if validation: cls_confs = convert2cpu(cls_confs.view(-1 , num_classes))
随后是一个解码的大循环,分析见下面的注释
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 for b in range (batch): boxes = [] for cy in range (h): for cx in range (w): for i in range (num_anchors): ind = b * sz_hwa + i * sz_hw + cy * w + cx det_conf = det_confs[ind] if only_objectness: conf = det_confs[ind] else : conf = det_confs[ind] * cls_max_confs[ind] if conf > conf_thresh: bcx = xs[ind] bcy = ys[ind] bw = ws[ind] bh = hs[ind] cls_max_conf = cls_max_confs[ind] cls_max_id = cls_max_ids[ind] box = [bcx / w, bcy / h, bw / w, bh / h, det_conf, cls_max_conf, cls_max_id] if (not only_objectness) and validation: for c in range (num_classes): tmp_conf = cls_confs[ind][c] if c != cls_max_id and det_confs[ind] * tmp_conf > conf_thresh: box.append(tmp_conf) box.append(c) boxes.append(box) all_boxes.append(boxes) return all_boxes
NMS部分 NMS也在utils.py中,函数名为nms。该函数中,首先实现对所有候选框的排序。这里使用det_confs获取了置信度从大到小的anchor box的坐标位置sortIds。
1 2 3 4 5 6 7 8 9 def nms (boxes, nms_thresh ): if len (boxes) == 0 : return boxes det_confs = torch.zeros(len (boxes)) for i in range (len (boxes)): det_confs[i] = 1 - boxes[i][4 ] _, sortIds = torch.sort(det_confs)
随后实现候选框的筛选,从高置信度的候选框开始遍历,对于每个候选框boxes[sortIds[i]],遍历所有置信度低于该候选框且置信度不为0(置信度为0表示该候选框被抛弃)的候选框,若低置信度候选框与高置信度候选框的IOU大于阈值,则抛弃低置信度候选框。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 out_boxes = [] for i in range (len (boxes)): box_i = boxes[sortIds[i]] if box_i[4 ] > 0 : out_boxes.append(box_i) for j in range (i + 1 , len (boxes)): box_j = boxes[sortIds[j]] if bbox_iou(box_i, box_j, x1y1x2y2=False ) > nms_thresh: box_j[4 ] = 0 return out_boxes