系统结构
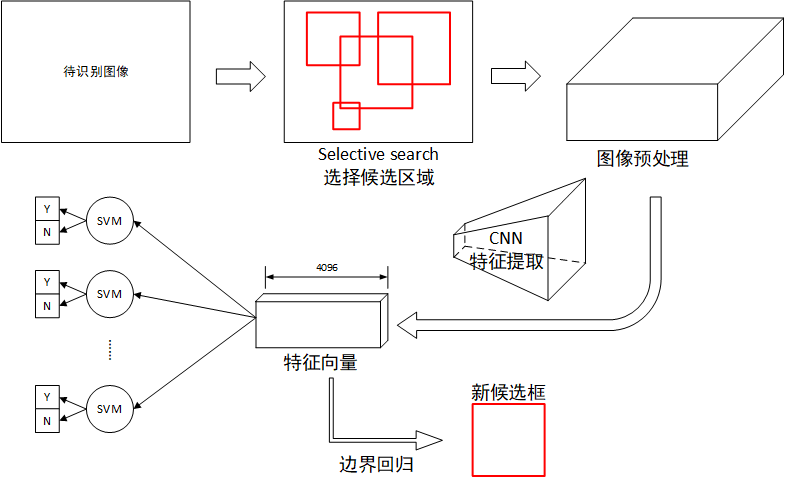
RCNN物品目标识别系统如上图所示,如图所示,共分为四步:
- 候选区域提取:使用Selective search选择候选区域,并进行预处理,全部处理为相同大小
- CNN特征提取:使用CNN将特征区域图像提取为一个特征向量
- SVM分类:使用支持向量机判断支持该候选区域是否属于某一个类别
- 边界回归:若确定某候选框属于某个类别,则使用回归的方式微调候选框的位置
候选区域提取
RCNN使用Selective search算法代替滑动框,该算法可以提取类别无关的物品候选区域。该算法分为以下步骤:
- 初始化一些小候选框
- 不断合并小候选框为大候选框,并保存所有未合并的候选框,产生一系列候选区域

具体算法如上文所示,首先产生一系列初始区域R,并计算R中所有相邻区域之间的评分s,保存在集合S中,随后不断合并最高评分的两个区域,最终产生一系列候选区域。
初始化
初始化的过程使用论文《Efficient graph-based image segmentation》过程中的方法,即使用无向图$G=(V,E)$表示一张图片,其中V表示所有无向图中所有像素,即令每一个像素对应一个顶点;E表示连接,仅有相邻的像素(顶点)之间才有连接,两个顶点之间的连接权值有不同的衡量标准。产生初始框的方式类似于类聚算法,类聚的依据如下所示:
类聚的依据为$D(C_1,C_2)$的结果,当为true时,即外部最小连接强度$Dif(C_1,C_2)$大于内部最大连接强度$MInt(C_1,C_2)$时,两个区域合并。若两个区域之间无连接,则外部链接强度为无穷大。
合并候选框
候选框的合并基于一个评分,若两个区域的评分高于某个阈值,则将这两个候选框合并,评分函数如下:
其中,${ax}(x=1,2,3,4)$为权值,表示每个部分的重要性;$s{i}$为评分分量:
- $s{colour}$:颜色分量,用于评价颜色关联性,计算方法为对所选区域不同颜色空间内进行横轴被分为n份(bin=n)的一维直方图统计,可得$C_i={c^1_i,c^2_i,…,c^n_i}$,$c_i^k$表示数据落在直方图第k个区域对应范围内的像素数量,最终区域i和j的颜色分量评分为$s{colour}(ri,r_j)=\sum\limits{k=1}^nmin(c_i^k,c_j^k)$
- $s{texture}$:纹理分量,用于评价纹理的关联性,使用Fast SIFT-like特征描述,与颜色分量类似做直方图统计,获得$T_i = {t_i^1,…,t_i^n}$,最终区域i和j的纹理分量评分为$s{texture}(ri,r_j) = \sum\limits^n{k=1}min(t_i^k,t_j^k)$
- $s{size}$:大小分量,$s{size}(r_i,r_j) = 1-\cfrac{size(r_i)+size(r_j)}{size(im)}$,用于优先考虑小尺寸图像的合并。size(im)为图片尺寸
- $s{fill}$:重叠分量,$s{fill} = 1 - \cfrac{size(BB{ij})-size(r_j)-size(r_i)}{size(im)}$,用于优先考虑重叠大的尺寸合并,im为整个图片,$BB{ij}$为两个区域合并后的矩形区域。
这一步合并完成后产生一系列候选框,测试集测试大约每张图片有2K个候选区域。
预处理
由于候选框的尺寸不同,而后续卷积神经网络的输入要求一定,因此需要一定的预处理将图片尺寸归一化,该系统中直接使用仿射变换将图片尺寸强行变为卷积神经网络要求的输入(不考虑保证长宽比)。需要注意的是,为了保留上下文,在原有候选框的基础上将候选框外周围16个像素范围内的候选框边缘也加入候选框中。
除了尺寸,预处理还包括减去平均值。
卷积神经网络
卷积神经网络在本系统中用于特征提取,该卷积神经网络输入尺寸为227X227X3,使用的色彩空间为RGB。输出为一个长度为4096的向量,即提取出的特征。该网络共有5个卷积层和2个全连接层。
支持向量机
支持向量机用于判断物品类别,针对每个类型训练一个二分类支持向量机,用于判断候选框是否属于某种类别。该支持向量机输入为特征向量,输出为二分类正例或反例。
边界回归
当支持向量机判断出该候选框属于某个类别后,使用该类别的边界回归器微调边框位置和大小,边界回归器的输入为卷积神经网络Pool5层的输出(即最后一层池化层的输出,第一层全连接的输入),输出调整因子$d_*(P)$:
其中,P为候选框的参数${Px,P_y,P_w,P_h}$,$\phi_5(P)$为卷积神经网络Pool5层的输出,$w$为权值,调整因子$d*(P)$包括四个部分:${d_x(P),d_y(P),d_w(P),d_h(P)}$,调整过程如下所示:
最终获得调整后的候选框${G_x,G_y,G_w,G_h}$。
模型训练
模型的训练包括三个部分,分别是作为特征提取器的CNN网络的训练、分类器SVM和边界回归器的训练。
CNN训练
CNN使用alexnet的5层卷积+3层全连接层的网络,首先在大型数据集上预训练,训练集使用ILSVRC2012的分类任务训练集。预训练完成后开始针对特定任务微调,微调对应过程如下:
- 网络结构修改:将原网络最后一层全连接层换为输出为N+1的全连接层(N为物品类别,+1表示背景),随机初始化最后一层全连接层参数。
- 标记:对于相对于真实标注IoU>0.5的候选框,认为为对应物体,否则为背景
- 训练参数:SGD优化算法,初始学习率0.001,batch尺寸为128(32个物品+96背景)
SVM训练
针对每种类型训练一个二分类SVM,用于根据特征向量判断该候选框中是否有该类型物品,训练的标记与CNN网络类似使用IoU判断,若与标记物品IoU大于0.3(该阈值可依据不同人物修改),则认为是正例,否则是反例。
边界回归器
边界回归器的训练基于以下公式:
其中,$t_*^i$为标签,使用以下公式计算:
其中G为物品标签中的相关位置数据,P为提取出的候选框的位置数据。
