基本思路
YOLOv2是YOLO的第二个版本,该物品检测系统仍然只需要“Look Once”,其整体结构如下所示:
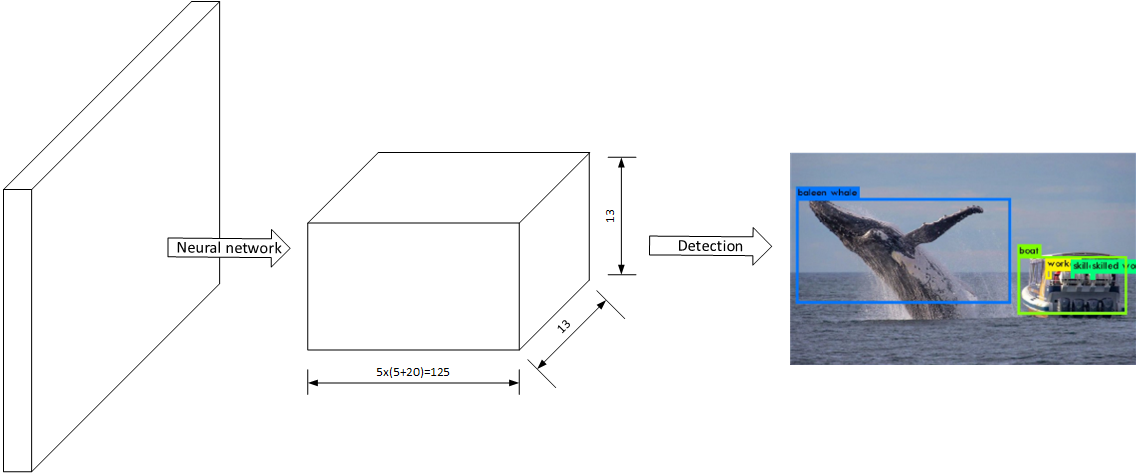
其主要由两个部分构成:
- 神经网络:将图片计算为一个$13\times 13 \times 125$的向量,该向量包含了预测的物品位置和类别信息
- 检测器:将神经网络输出的向量进行“解码”操作,输出物品的分类和位置信息。
神经网络部分
YOLOv2的神经网络部分使用了一个带跳层的神经网络,具体结构如下所示:

神经网络的设计没有太大飞跃性的改变,相对于YOLOv1的神经网络设计主要有以下改变:
- 每个卷积层后添加了批标准化层,加速了网络的收敛。
- 在第16层开始分为两条路径,将低层的特征直接连接到高层,可提高模型性能。
- 移除全连接层,最终的输出向量中保存了原来的位置信息。
- 输入尺寸变为$416\times 416 \times 3$,识别更高分辨率的图片。
该网络最终输入图片尺寸为,$416\times 416 \times 3$输出向量尺寸为$13 \times 13 \times 125$。
检测器部分
YOLOv2使用了Anchor Box的方法,神经网络输出的向量尺寸是$13\times 13 \times 125$,其中$13 \times 13$是将图片划分为13行和13列共169个cell,每个cell有125数据。对于每个cell的125个数据,分解为$125 = 5 \times (5+20)$,即每个cell包括5个anchor box,每个anchor cell包括25个数据,分别为物品存在置信度,物品中心位置(x,y),物品尺寸(w,h)和类别信息(20个)。如下图所示:
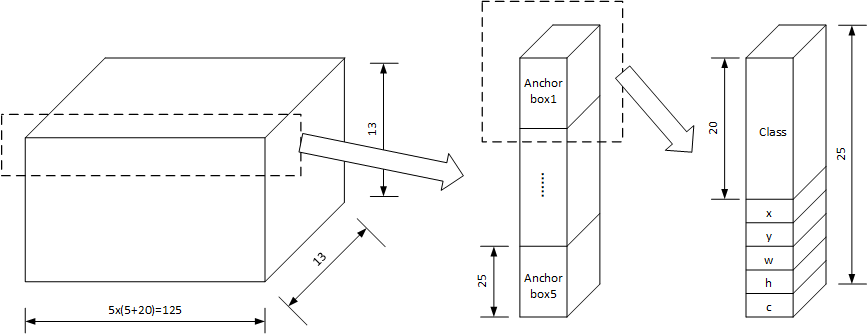
对于每个cell包括5个anchor box信息,每个anchor box包括25个数据,分别:
- 为是否有物品(1个)
- 物品位置(4个)
- 物品种类(20个)
其中是否有物品的标记$conf_{ijk}$比较容易理解,表示位于$i,j$cell的第k个anchor box中有物品的置信度。20个物品种类向量也较好理解,哪一个数据最大即物品为对应的类别。
对于物品位置的四个数据分别为$x{ijk},y{ijk},w{ijk},h{ijk}$,与物品位置中心点和尺寸的关系为:
其中,$b_x,b_y$为物品中心点的实际坐标,$b_w,b_h$为物品的尺寸(长宽)。$c_x,c_y$的为该cell(x行y列)距离图片左上角的像素数,f的含义推测为将范围为0~1的输入值缩放到0~cell长度。$p_w$和$p_h$为该anchor box的预设尺寸。如下图所示:
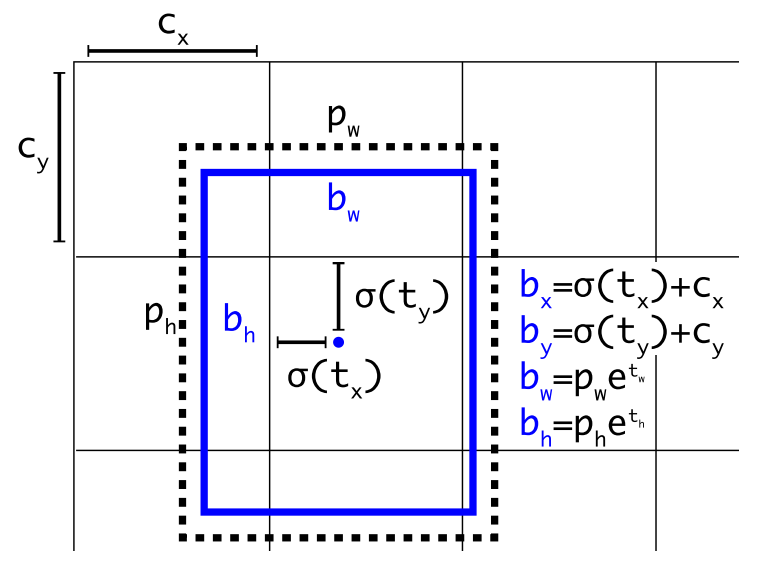
每个cell包括5个anchor box,这5个anchor box有不同的预设尺寸,该预设尺寸可以手动指定也可以在训练集上训练获得。在YOLOv2中,预设尺寸是通过在测试集上进行类聚获得的。
模型训练
神经网络部分基于模型Darknet-19,该模型的训练部分分为两个部分:预训练和训练部分
- 预训练:预训练是在ImageNet上按分类的方式进行预训练160轮,使用SGD优化方法,初始学习率0.1,每次下降4倍,到0.0005时终止。除了训练224x224尺寸的图像外,还是用448x448尺寸的图片。
- 训练:去除Darknet的最后一个卷积层,并将网络结构修改为YOLOv2的网络,在VOC数据集上进行训练。训练使用的代价函数是MSE代价函数。
另外,在训练过程中,还引入了多尺寸训练,由于网络删除了全连接层,所以该网络并不关心图片的具体大小,训练时使用320~608尺寸的图像{320,352,….,608}。
YOLOv3
YOLOv3是YOLO最新的更新,其主要的改进在以下方面:
- 网络结构改变:网络的结构由Darknet-19变为Darknet-53,跳层的现象越来越普遍。
- 尾部激活函数改变:尾部的激活函数(类别预测)由softmax改为sigmoid
- 尺度数量改变:anchor box的数量由5个改为3个
网络
网络结构如下所示:
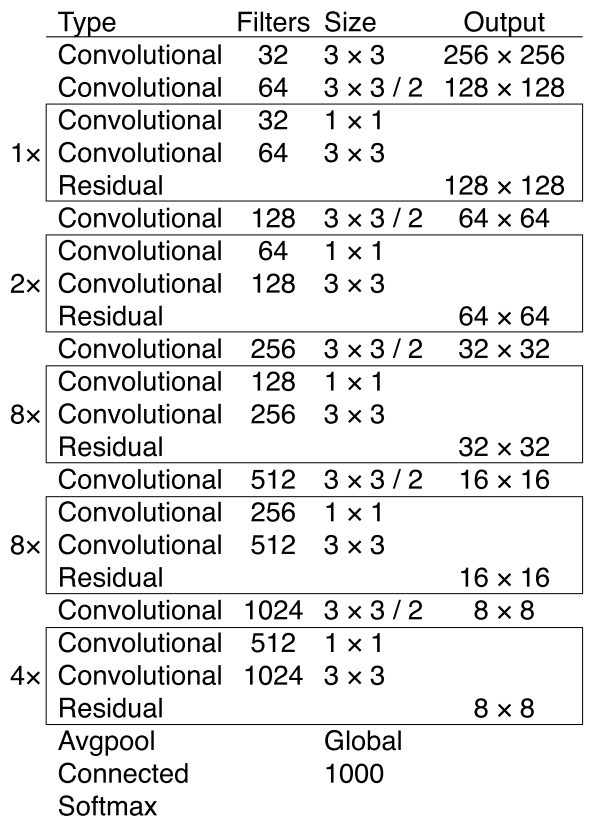
网络结构明显参考了ResNet的设计,将低层的特征直接连接到高层。同时注意一点,网络可能没有使用pool层,而是使用stride=2的卷积层实现下采样。
