1.模型
感知机的模型如下图所示:
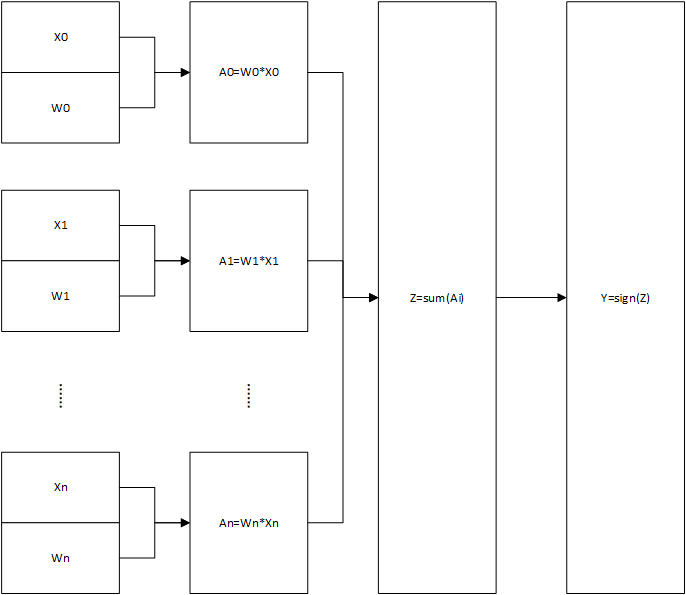
公式表示如下所示:
对于该分类器,其假设空间为特征空间的所有线性分类器,从几何学的角度可以理解为是特征空间中所有的超平面。那么,只要样本在特征空间中是线性可分的(可以被一个超平面完美划分),由感知机的假设空间,那么这个超平面一定在假设空间内,所以感知机是可以用于区分所有线性可分的样本。
2.学习策略
2.1.代价函数
感知机的目标是为了找到那个能完美划分线性可分样本的超平面。为了达到这个目标,我们需要定义代价函数。代价函数的意思是该函数刻画的是模型的性能,通常需要满足以下条件:
- 条件一:模型性能越好,代价函数越小,模型性能越差,代价函数越大
- 条件二:连续可导
条件一是使代价函数可以刻画模型性能,条件二是为了该模型可以使用梯度下降的方法优化
2.2.感知机代价函数选择
对于感知机,选取代价函数为:
其中M为分类错误的样本集合。对于该代价函数,显而易见是连续可导的,且当分类错误的时候$y_i$和$w \cdot x_i + b$异号,代价为正。则当模型性能好时,M中样本少,代价较小;模型性能差时,M中样本多,代价较大。
该代价函数还可以从几何学角度解释,空间中任意一点$x_0$到超平面的距离为:
由此,错误分类的样本$y_i$和$w \cdot x_i + b$异号,由此有以下:
取M为分类错误样本集合,则所有分类错误的样本到超平面距离如下:
不考虑常数$\cfrac{1}{||w||}$,则可以获得感知机代价函数$L(w,b) = - \sum\limits_{x_i \in M}y_i(w \cdot x_i + b)$
3.学习算法
3.1.基本算法
感知机算法是错误驱动的,由以上的代价函数,感知机的学习算法变为:
为了使代价函数下降最快,向代价函数的负梯度方向优化w和b。对代价函数取w和b的梯度:
由此可获得更新方法:
其中,$\eta$为学习率,表示每一次更新的步长,学习率越大更新越明显。由此,每次选择一批错误分类的点,进行上述的优化,多次循环即可学得可以正确分类的感知机模型
3.2.对偶算法
将梯度表达式带入更新公式:
若w和b的初始值都是0,$\eta = 1$,则可以认为w是错误样本的$y_i \cdot x_i$的和,b是错误样本标签的和,由此可以得到以下公式:
其中$a_i$是该样本被错误分类的次数,可以发现,分类错次数越多的样本在参数中所占的比例越大。则每次选择一批数据输入,将分类错误的样本按更新公式计入参数,重复多次直到无错误样本即可。
4.延伸
4.1.感知机与支持向量机
感知机的对偶优化算法已经有一些支持向量机思想的影子——只有少数“关键样本”决定分类器超平面的位置,其他的样本并不重要,有对偶算法得到的w和b公式:
可以将$a_i$视为样本的权值,分类错误次数越多该权值$a_i$越大,即该样本越重要。很自然的可以想到距离最终超平面越近的样本越容易分类错,这种样本的权值也就越高,这些样本也就越重要。
4.2.感知机与神经网络
感知机是神经网络的基础,感知机也被成为单层神经网络。感知机的一大缺陷是无法解决线性不可分问题,想要解决这一问题,需要将原来线性不可分的样本映射到另一个特征空间去,在该空间样本线性可分,映射方法主要有两种:
- 人工指定映射方法:手动指定映射的方法,代表为核函数(核方法)
- 自动寻找映射方法:使用机器学习的方法自动获得映射方法,代表为神经网络
神经网络可以分解如下:
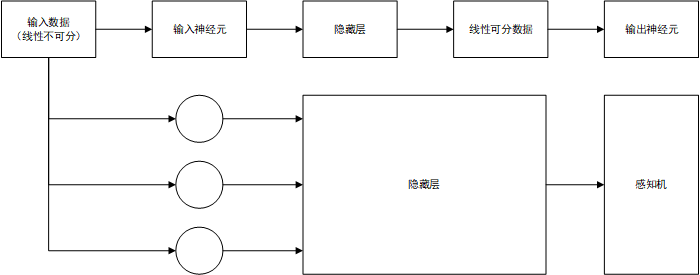
当输入是线性不可分样本时,通过复杂的隐藏层(全连接层,卷积层或胶囊层)层层映射,最终在输出层之前将数据映射到一个线性可分的特征空间中,再由感知机进行线性分类。其中映射方法由神经网络自行学得。所有输出层为感知机层的神经网络都可以放在这个框架下理解。
除此以外,感知机还奠定了神经网络的基础理论。例如神经网络的基本学习框架也是梯度下降:使用反向传播计算梯度,优化算法迭代获得新的参数。
参考文献
《统计学习方法》李航
