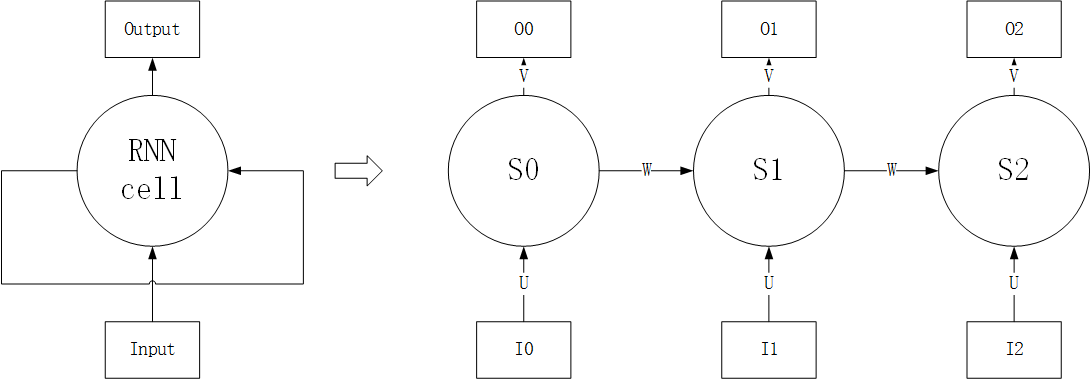
RNN理论基础 基本RNN结构 RNN的基本结构如上左图所示,输出除了与当前输入有关,还与上一时刻状态有关。RNN结构展开可视为上右图,传播过程如下所示:
$ I_{n} $ 为当前状态的输入
$ S{n} $ 为当前状态,与当前输入与上一时刻状态有关,即 $ S {n} = f(W \times S{n - 1} + U \times I {n}) $ ,其中f(x)为激活函数
$ O{n} $ 为当前输出,与状态有关,为 $ O {n} = g(V \times S_{n}) $ ,其中f(x)为激活函数
整个结构共享参数U,W,V。
当输入很长时,RNN的状态中的包含最早输入的信息会被“遗忘”,因此RNN无法处理非常长的输入
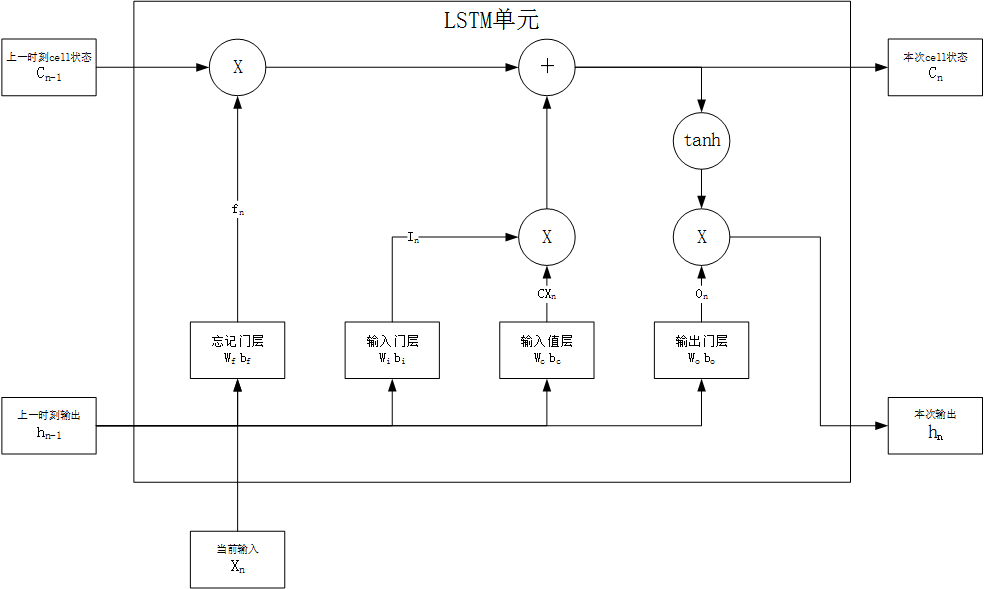
基本LSTM结构 LSTM为特殊为保存长时记忆而设计的RNN单元,传递过程如下:
遗忘:决定上一时刻的状态有多少被遗忘,由遗忘门层完成,有 $ f{n} = sigmoid(W {f} \times [h{n-1},x {n}] + b{f}) $ ,该结果输出的矩阵与 $ C {n-1} $ 对应位置相乘,对状态起衰减作用
输入:决定哪些新信息被整合进状态,由输入值层和输入门层完成:
输入值层决定新输入数据,有 $ CX{n} = tanh(W {c} \times [h{n - 1},x {n}] + b_{c}) $
输入门层决定哪些新数据被整合入状态,有 $ I{n} = sigmoid(W {i} \times [h{n - 1},x {n}] + b_{i}) $
最终汇入状态的输入有 $ C{n} = C {n-1} \times f{n} + I {n} \times CX_{n} $
输出:决定哪些状态被输出,由输出门层完成:
输出门层决定哪些状态被输出,有 $ O{n} = sigmoid(W {o} \times [h{n-1},x {n}] + b_{o}) $
最终输入为 $ h{n} = O {n} \times tanh(C_{n}) $
参数一共有4对,如下表所示
参数功能
参数对
忘记门层,决定哪些状态被遗忘
$ W{f} $ , $ b {f} $
输入门层,决定哪些新输入被累积入状态
$ W{c} $ , $ b {c} $
输入值层,产生新输入
$ W{i} $ , $ b {i} $
输出门层,决定哪些状态被输出
$ W{o} $ , $ b {o} $
代码实现 导入数据 下载数据 1 2 3 4 5 6 7 8 9 10 11 12 13 import osimport requestsdef download_data (url,name ): if not os.path.exists(name): file_content = requests.get(url) with open (name,"wb" ) as f: f.write(file_content.content) download_data("https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/ptb/ptb.train.txt" ,"./ptb.train.txt" ) download_data("https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/ptb/ptb.valid.txt" ,"./ptb.valid.txt" ) download_data("https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/ptb/ptb.test.txt" ,"./ptb.test.txt" ) download_data("https://raw.githubusercontent.com/dmlc/web-data/master/mxnet/tinyshakespeare/input.txt" ,"./input.txt" )
数据处理函数 1 2 3 4 5 6 def tokenize_text (fname, vocab=None , invalid_label=-1 , start_label=0 ): lines = open (fname).readlines() lines = [filter (None , i.split(' ' )) for i in lines] sentences, vocab = mx.rnn.encode_sentences(lines, vocab=vocab, invalid_label=invalid_label, start_label=start_label) return sentences, vocab
可迭代数据生成 1 2 3 4 start_label = 1 invalid_label = 0 train_sent, vocab = tokenize_text("./ptb.train.txt" , start_label=start_label,invalid_label=invalid_label) val_sent, _ = tokenize_text("./ptb.test.txt" , vocab=vocab, start_label=start_label,invalid_label=invalid_label)
1 print(type (vocab),len (vocab))
<class 'dict'> 10000
1 print(type (train_sent),train_sent[:5 ])
<class 'list'> [[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 0], [25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 27, 0], [39, 26, 40, 41, 42, 26, 43, 32, 44, 45, 46, 0], [47, 26, 27, 28, 29, 48, 49, 41, 42, 50, 51, 52, 53, 54, 55, 35, 36, 37, 42, 56, 57, 58, 59, 0], [35, 60, 42, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 35, 71, 72, 42, 73, 74, 75, 35, 46, 42, 76, 77, 64, 78, 79, 80, 27, 28, 81, 82, 83, 0]]
1 2 3 4 5 batch_size = 50 buckets = [10 ,20 ,40 ,60 ,80 ] data_train = mx.rnn.BucketSentenceIter(train_sent, batch_size, buckets=buckets,invalid_label=invalid_label) data_val = mx.rnn.BucketSentenceIter(val_sent, batch_size, buckets=buckets,invalid_label=invalid_label)
WARNING: discarded 4 sentences longer than the largest bucket.
WARNING: discarded 0 sentences longer than the largest bucket.
1 2 3 for _,i in enumerate (data_train): print(i.data[0 ][:2 ],i.label[0 ][:2 ]) break
[[ 1203. 373. 141. 119. 79. 64. 32. 891. 80. 4220.
3864. 119. 1407. 860. 467. 1930. 42. 668. 0. 0.]
[ 35. 114. 81. 5793. 119. 840. 432. 1516. 232. 926.
181. 923. 5845. 225. 98. 0. 0. 0. 0. 0.]]
<NDArray 2x20 @cpu(0)>
[[ 373. 141. 119. 79. 64. 32. 891. 80. 4220. 3864.
119. 1407. 860. 467. 1930. 42. 668. 0. 0. 0.]
[ 114. 81. 5793. 119. 840. 432. 1516. 232. 926. 181.
923. 5845. 225. 98. 0. 0. 0. 0. 0. 0.]]
<NDArray 2x20 @cpu(0)>
可以发现,可迭代数据的label为下一时刻(data向左平移一个单词)的数据
模型建立 1 2 3 4 5 num_layers = 2 num_hidden = 256 stack = mx.rnn.SequentialRNNCell() for i in range (num_layers): stack.add(mx.rnn.LSTMCell(num_hidden=num_hidden, prefix='lstm_l%d_' %i))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 num_embed = 256 def sym_gen (seq_len ): data = mx.sym.Variable('data' ) label = mx.sym.Variable('softmax_label' ) embed = mx.sym.Embedding(data=data, input_dim=len (vocab),output_dim=num_embed, name='embed' ) stack.reset() outputs, states = stack.unroll(seq_len, inputs=embed, merge_outputs=True ) pred = mx.sym.Reshape(outputs, shape=(-1 , num_hidden)) pred = mx.sym.FullyConnected(data=pred, num_hidden=len (vocab), name='pred' ) label = mx.sym.Reshape(label, shape=(-1 ,)) pred = mx.sym.SoftmaxOutput(data=pred, label=label, name='softmax' ) return pred, ('data' ,), ('softmax_label' ,)
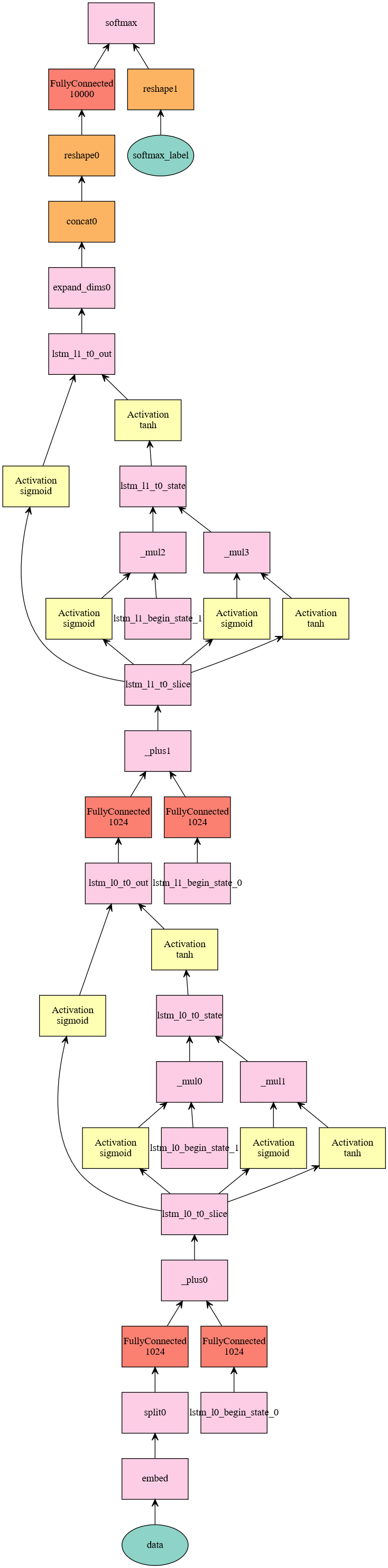
1 2 3 a,_,_ = sym_gen(1 ) mx.viz.plot_network(symbol=a)
训练网络 1 2 3 import logginglogging.getLogger().setLevel(logging.DEBUG) model = mx.mod.BucketingModule(sym_gen=sym_gen,default_bucket_key=data_train.default_bucket_key,context=mx.gpu())
1 2 3 4 5 6 7 8 9 10 11 12 model.fit( train_data = data_train, eval_data = data_val, eval_metric = mx.metric.Perplexity(invalid_label), kvstore = 'device' , optimizer = 'sgd' , optimizer_params = { 'learning_rate' :0.01 , 'momentum' : 0.0 , 'wd' : 0.00001 }, initializer = mx.init.Xavier(factor_type="in" , magnitude=2.34 ), num_epoch = 2 , batch_end_callback = mx.callback.Speedometer(batch_size, 50 , auto_reset=False ))
WARNING:root:Already bound, ignoring bind()
WARNING:root:optimizer already initialized, ignoring.
INFO:root:Epoch[0] Batch [50] Speed: 240.74 samples/sec perplexity=1230.415304
INFO:root:Epoch[0] Batch [100] Speed: 203.97 samples/sec perplexity=1176.951186
INFO:root:Epoch[0] Batch [150] Speed: 222.01 samples/sec perplexity=1161.217528
INFO:root:Epoch[0] Batch [200] Speed: 214.61 samples/sec perplexity=1130.756199
INFO:root:Epoch[0] Batch [250] Speed: 209.55 samples/sec perplexity=1109.315310
INFO:root:Epoch[0] Batch [300] Speed: 213.95 samples/sec perplexity=1093.083615
INFO:root:Epoch[0] Batch [350] Speed: 232.20 samples/sec perplexity=1084.233586
INFO:root:Epoch[0] Batch [400] Speed: 202.13 samples/sec perplexity=1069.696013
INFO:root:Epoch[0] Batch [450] Speed: 218.14 samples/sec perplexity=1057.711184
INFO:root:Epoch[0] Batch [500] Speed: 236.57 samples/sec perplexity=1048.120406
INFO:root:Epoch[0] Train-perplexity=1044.812667
INFO:root:Epoch[0] Time cost=118.042
INFO:root:Epoch[0] Validation-perplexity=853.844612
INFO:root:Epoch[1] Batch [50] Speed: 228.59 samples/sec perplexity=932.793729
INFO:root:Epoch[1] Batch [100] Speed: 210.51 samples/sec perplexity=933.630035
INFO:root:Epoch[1] Batch [150] Speed: 215.88 samples/sec perplexity=941.272076
INFO:root:Epoch[1] Batch [200] Speed: 226.13 samples/sec perplexity=937.232755
INFO:root:Epoch[1] Batch [250] Speed: 199.27 samples/sec perplexity=926.975004
INFO:root:Epoch[1] Batch [300] Speed: 196.35 samples/sec perplexity=913.408955
INFO:root:Epoch[1] Batch [350] Speed: 216.76 samples/sec perplexity=907.031329
INFO:root:Epoch[1] Batch [400] Speed: 198.65 samples/sec perplexity=899.224687
INFO:root:Epoch[1] Batch [450] Speed: 238.68 samples/sec perplexity=896.943083
INFO:root:Epoch[1] Batch [500] Speed: 205.63 samples/sec perplexity=892.764729
INFO:root:Epoch[1] Batch [550] Speed: 206.36 samples/sec perplexity=888.453916
INFO:root:Epoch[1] Batch [600] Speed: 218.98 samples/sec perplexity=885.808878
INFO:root:Epoch[1] Batch [650] Speed: 229.98 samples/sec perplexity=884.451112
INFO:root:Epoch[1] Batch [700] Speed: 226.57 samples/sec perplexity=882.243212
INFO:root:Epoch[1] Batch [750] Speed: 234.16 samples/sec perplexity=878.481937
INFO:root:Epoch[1] Batch [800] Speed: 218.44 samples/sec perplexity=874.363066
INFO:root:Epoch[1] Train-perplexity=869.764287
INFO:root:Epoch[1] Time cost=194.924
INFO:root:Epoch[1] Validation-perplexity=747.663144
参考文献 [译] 理解 LSTM 网络
RNN的入门烹饪指南
[翻译] WILDML RNN系列教程 第一部分 RNN简介
[莫烦 PyTorch 系列教程] 4.3 - RNN 循环神经网络 (回归 Regression)
MXnet官方例程